

by Andy James
A quick search on the internet will yield many legitimate reasons to move to the cloud. Five of the most prominent are:
- Scalability
- Flexibility
- Updates
- Security
- Cost
The Intersection of Cloud and Seismic Data
Oil and gas companies are dealing with petabytes of seismic data. Typically, 85% of their total data is seismic, stored in different formats, both offline and online, across many locations.
How can the cloud help with subsurface data management? While all five factors I mentioned earlier are important, scalability and cost stand out above the others.
One of the cloud-storage options is object storage, which is designed to be highly scalable. It can handle massive libraries of data. Think about video content on Netflix or all the image content on Instagram!
Object storage is cheap too. When comparing retail costs for cloud object store, as noted in Table 1, you have a choice between hot or cold. For example, storing one petabyte of data in hot storage is more expensive compared to cold storage. The trade-off with cold storage is that you must thaw it before you can use it.
Table 1: Cloud Object Store Retail Cost Comparison
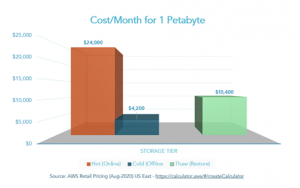
Note these numbers change frequently but can be found online using cloud vendor pricing calculators.
When placing data in object storage, a trade-off between the low cost of cold storage and the frequency of thawing needs to be made. It’s easy to look at the cost of archive and see why moving data to cloud archive is attractive.
Digital Transformation
Think about the digital transformations that have occurred with music and video media. Moving data from legacy storage formats such as VHS tape into new MP4 formats and leveraging compression along with cloud streaming has enabled a significant digital transformation. Streaming television services such as Netflix, Amazon Prime Video, Hulu, and YouTube have completely transformed the way we watch TV today.
This transformation led to the demise of Blockbuster rapidly as Netflix pioneered a new business model. Last year, Netflix had an annual revenue of $5.2 billion, which is increasing swiftly. Blockbuster, on the other hand, went from a peak of 5,710 stores, to one store remaining today, which is essentially a museum paying homage to a forgotten past.
Digitalization Goal
I conducted research around what it means to have a cloud digitalization goal, and this is what stood out to me most: ‘Accelerate Innovation Across the Enterprise.’
Ask yourself, ‘What is the goal of moving seismic data to the cloud?’ In the past, we ripped our CD’s to MP3, so that we could play them on new and exciting media players. There needs to be a clear goal.
By migrating seismic data to the cloud, are we selling our enterprise short? We may be saving money by moving data to the cloud, but have we really accelerated innovation across the enterprise? More importantly, have we enabled our employees or customers to derive value directly from this move?
Using Seismic Data in the Cloud
Data access with a geophysical workload has a significant impact on the overall performance and speed of the application. If we move the data away from applications, we end up with a diminished experience for the user. It is possible to move applications to the cloud by virtualizing the geoscience workstation. Cloud vendors have offered virtualized workstations for years. More recent updates have provided high-end GPU-based workstations and technologies that enable 3D visualization with performance as if you were sitting next to the workstation. Simply amazing!
But I ask again, have we really accelerated innovation across the enterprise? Applications are virtualized, and the seismic data is in the cloud, but so what? It’s the same workflow in the cloud. The challenge is that geoscience applications do not work with object store.
Geoscience applications were invented before the cloud existed. They expect files to be available on normal file systems. Moving applications to the cloud doesn’t allow connectivity directly to the cloud objects. There are workarounds, but these aren’t performant. Oil and gas companies find themselves deploying traditional high-performance file systems within the cloud to replicate the on-premise solution. This is a classic lift and shift, where we move seismic files onto a file system, and seismic applications onto a virtual workstation. The result is moving the whole workload to the cloud with little to no accelerated innovation across the enterprise.
Digging deeper, we must consider the cost of moving the workflow to the cloud independently from moving the data. The cost of high-performance file systems required to deliver the data to geoscience applications on the virtual workstation increases by over 20 times when compared to object store.
When moving data to the cloud, we fixate on the archive cost, which is incredibly cheap and not on the cost of moving, copying, and using the data on expensive network storage in the cloud.
Streaming Seismic Data
So, what is the path forward? How do we really transform our seismic workflows? Streaming data from the cloud is an established technology that is used by video streaming services today. What if we apply the same approach to seismic data where we use compression with adaptive signal quality streaming to deliver data directly into geophysical applications? This enables a central source of data to be delivered into the application, on-demand.
To achieve the same transformation as seen within the media space, we must change the seismic data format to a cloud-native format, such as OpenVDS. OpenVDS is supported by The Open Group OSDU™ Forum Data Platform and is a subset of Bluware’s existing Volume Data Store (VDS™) commercial implementation.
OpenVDS is core to making these types of transformations achievable and is one of the open-source data formats for seismic data available today through the OSDU Data Platform. Many independent software vendors already see the benefits of this transformative format and made integrations with OpenVDS within their application, such as Interactive Network Technologies, Inc. (INT) in their IVAAP product and Subsurface.io in their data management tool. The latest version supports post stack seismic data, and updates are being made to store all E&P volume data types such as regularized single-z horizons/height-maps, seismic lines, pre-stack volumes, geo-body volumes, and attribute volumes of any dimensionality up to 6D. The Python and C++ APIs support reading and writing OpenVDS, so data scientists have rapid, random access to data.
This provides an alternative to storing seismic data in the cloud as a file within a single object, which then needs to be copied to an expensive, high-performance disk to be used within a geophysical application in the cloud.
Since OpenVDS is serverless, the data is spread across hundreds of thousands of objects and blazing fast adaptive streaming technology is used to deliver data to a transcoder, which sits as a service on the virtual workstation. Flexible Access Storage Transcoder™ (FAST), delivers data directly into a geophysical application without the application being aware that it is not reading from a file itself. This enables you to not only move geophysical applications to the cloud, it enables you to access data directly from the cheapest form of storage, namely the object store.
FAST is analogous to the Netflix app. Data is streamed to the FAST application from a central repository, which could be your OSDU Data Platform environment. Then, it is delivered into a format the application can use while directly reading from the cheaper object storage, which is also your central source for all of your seismic data. The data that is streamed is cached locally on the very fast VM SSD, making geophysical applications even more performant, and significantly reducing costs by avoiding any intermediate file storage. Support is available for most popular applications such as Petrel, Paleoscan, and others.
Moving petabytes of data to the cloud can be very cost-effective when achieved as part of a digital transformation with clear goals using transformative technologies. If companies work together and adopt a single cloud format, the whole industry wins, and we can all share the goal to accelerate innovation across the enterprise.
Andy James, Chief Product Officer at Bluware

Andy James has 30 years of oil and gas experience which have been focused on technology leadership roles. He has extensive experience in commercial software delivery, product management, and product life cycle. Mr. James joined Bluware in February 2019, prior to which he served 10 years at IHS Markit where he led the global software development organization for the upstream oil and gas business. Key contributions include leading the geoscience software organization, migration of key platform technologies to the cloud, and Agile development transformation. Mr. James also spent 20 years in global roles in London, Holland, and Houston with Halliburton, including stints with KBR, Halliburton Integrated Solutions, and finally Landmark Graphics.
Andy James can be reached at andy.james@bluware.com or via Linkedin, here.